Статья о практическом использовании контент-анализа, на наш взгляд, будет интересна занимающимся не только конкурентной разведкой, но и управлением вообще, в том числе маркетингом, рекламной деятельностью и т. д.
Чтение между строк
(контент-анализ в конкурентной разведке, и не только в ней)[1]
Ю. П. ВОРОНОВ,кандидат экономических наук,
вице-президент Новосибирской торгово-промышленной палаты,
генеральный директор консультационной фирмы «Корпус»
Анализ открытых источников информации о конкурентах возвращает нас к чтению между строк — любимому занятию интеллектуалов в советские времена. В отличие от любительских попыток советских хитрецов вычитать то, что напрямую не написано, в конкурентной разведке для этого используется ряд методических приемов. Начнем с метода контент-анализа. Не будем перечислять его определения, ограничимся тем, что это — формальный анализ содержания текста. Будет проще и понятнее, если я расскажу, как впервые познакомился с его практическими приложениями.
ЦРУ и письма сибирских крестьян
Вторая половина 60-х годов — романтический период развития советской социологии. Впервые государство разрешило опрашивать население и перестало засекречивать материалы опросов. Совершенствовались методики исследований, совместно с Госкомстатом проводились массовые анкетные опросы.
И как-то «в струю» попала тогда толстенная книга исследователей из Массачусетского технологического института, которая называлась General Inquirer («Общий исследователь»). В книге описывались результаты массового компьютерного анализа текстов, да каких! Например, в одной из глав рассказывалось о том, как ЦРУ отслеживает высказывания о США в региональных печатных изданиях КНР. Результат работы программы компьютерного контент -анализа показан на рис. 1.
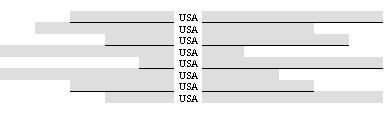
Рис. 1. Пример результата анализа китайских газет, проводившегося учеными Массачусетского технологического института (США) в 60-е годы прошлого века
Теперь представим, что вместо USA стоит наименование фирмы-конкурента, а строчки (на рис. 1 они — пустые) взяты из местной прессы. Если вы руководитель фирмы и экономите деньги, не выделяя их на более сложную систему обработки, и этот метод даст результаты. Если же вы занимаетесь конкурентной разведкой, то перед вами — сырье для добротной аналитической справки.
В книге «General Inquirer», названной так, кстати, по имени программы, анализирующей тексты, до сих пор можно найти много полезного для оперативного компьютерного анализа текстовых сообщений.
Вторая встреча с практическим применением контент -анализа состоялась также давно. Крупной вехой в истории мировой социологии была книга канадского социолога Томаса и польского статистика Знанецкого «Польский крестьянин в Европе и Америке», где собраны и проанализированы письма польских крестьян, уехавших в Канаду. Получилось два тома качественной аналитики, количественных соотношений там не было.
Потом я узнал, что Ян Знанецкий изучал и письма поляков, уехавших в Сибирь, в рамках государственной программы, организованной Переселенческим комитетом. Для меня труды Переселенческого комитета по анализу писем новых сибиряков — образец практического использования контент-анализа. В Санкт-Петербурге аналитики рассчитывали модельную схему переселения в Сибирь типичной крестьянской семьи, ее затраты и доходы. На основании этих расчетов принимались решения, например, о минимальном пособии на переезд в зависимости от числа членов семьи, об оптимальном размере выделяемого земельного участка, о наилучших сроках выезда и даже о финансировании государством паромных переправ через Волгу, Иртыш и Обь.
Благодаря, в частности, и его деятельности положительное сальдо миграции в Сибирь несколько лет выдерживалось на уровне миллиона человек в год[2].
Впоследствии подобные методики активно использовались в годы Второй мировой войны.
Немного теории
Социологические методики активно используют так называемые проективные процедуры. Например, человека спрашивают: «Купили бы вы этот товар, если бы он был на 20% дороже?»[3]. В такую вымышленную ситуацию человек всегда привносит некоторую личностную окраску, собственную трактовку, он проецирует свои будущие ощущения и действия[4]. Значение, которое получено в результате такого сугубо личного восприятия, называется коннотативным. Оно связано с предыдущим жизненным опытом, со сложившимися стереотипами и текущими эмоциями, поэтому любой текст содержит информацию о его авторе.
Второй теоретический элемент, на котором базируется контент-анализ, — это синестезия, т. е. перенос категорий из одной сферы в другую. Чтобы понять, о чем идет речь, вспомним обороты типа: «бархатный голос», «твердая убежденность», «теплые отношения», «кислая рожа», «черная зависть» и т. п. Еще пример — эксперт вполне может оценить супермаркет конкурента как «занудный и печальный», и в этом уже будет содержаться скрытая рекомендация о том, как данного конкурента победить. Синестезия выходит за пределы языкознания, в сферу психологии и социальной психологии. Механизмы синестезии признаются всеми науками о человеке.
Экспериментально доказано, что обозначения цветов устойчиво связаны с такими категориями, как «хороший — плохой», «сильный — слабый» и «активный — пассивный» (табл. 1). (Разумеется, это относится к западному варианту коннотатива цветов, в Азии или на Среднем Востоке результаты будут другими.)
Таблица 1
Kоннотативные значения цветов[5]
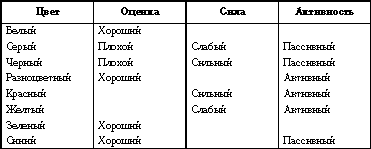
По упоминаниям о цвете в высказываниях, текстах и выступлениях конкурента, равно как по цвету в оформлении, фирменном стиле и т. д. можно получить представление о том, что подразумевается между строк, например, пессимистичны или оптимистичны оценки будущего.
Последующие исследования показали, что эмоциональное отношение к цвету никак не связано со свойствами глаза или спектральными характеристиками цвета и объясняется исключительно психологическими факторами. Кстати, оно не исчерпывается тремя указанными характеристиками (оценка, сила, активность).
Наиболее активный современный российский исследователь в сфере прикладного контент-анализа В. И. Шалак занимается преимущественно приложениями этого метода в политической сфере. Разработанная по его идеям система ВААЛ отслеживает большинство распространенных в русском языке коннотативов. На меня наибольшее впечатление произвело его исследование частоты встречаемости в текстах предлогов «к» и «от». Эта работа находится на грани контент-анализа и нейролингвистического программирования. Выводы автора сводятся к тому, что если в текстах (или речи) чаще встречается предлог «к», то человек ориентирован на будущее. Если же чаще встречается предлог «от», то его в большей степени волнуют события прошлого.
Применительно к конкурентной разведке результаты этого исследования сводятся к следующему. Пусть у вас есть два почти равнозначных конкурента, и вы знаете, что кто-то из них затеял против вас какую-то хитрую комбинацию. Тогда простой подсчет соотношения предлогов «к» и «от» в выступлениях двух руководителей способен выделить из них подозреваемого.
Теперь перейдем к обсуждению возможностей использования контент-анализа в конкурентной разведке.
Реклама и объявления о приеме на работу
Наиболее прост анализ самых распространенных сообщений конкурента — объявлений о приеме на работу. Он сводится к тому, что на каждое сообщение, опубликованное в рекламных изданиях, накладывается макет (фрейм) — краткая анкета, содержащая, например, следующие вопросы:
указывается или нет зарплата, если да, то какая?
является ли информативным название рабочего места, на которое объявляется прием кандидатов? О чем может говорить это название?
говорится ли в сообщении о перспективах и карьере? В какой форме?
чем данное сообщение о приеме на работу принципиально отличается от аналогичных предыдущих сообщений?
какой телефон указывается — кадровой или иной службы?
Сама структура объявления информативна — например, какими способами компания-конкурент рассчитывает привлекать персонал, — большой зарплатой, карьерой или интересной работой?
Написание объявления о приеме на работу является частным случаем проективной методики. Автор прогнозирует: кто может откликнуться на него, каких кандидатов он желал бы видеть, а на каких не хотел бы тратить время[6]. Задача аналитика состоит в том, чтобы восстановить эту картину и построить на ее основании возможную тактику своей компании.
Прелесть объявлений о приеме на работу как источника информации о конкуренте состоит еще и в том, что всегда можно позвонить по указанному телефону и постараться «добрать» недостающую информацию. Второй элемент привлекательности — разный уровень возможных рекомендаций, вытекающих из анализа сообщений конкурента о приеме на работу. Это могут быть рекомендации по конкурентным операциям в кадровой сфере. Например, рекомендации назначать тем, кого принимают в вашу компанию, не меньшую или даже более высокую зарплату.
Второй по важности открытый источник информации о конкуренте — рекламные сообщения. Их особенность состоит в смеси правдивых сообщений и обязательного для рекламы налета блефа.
Информативен не только текст рекламного сообщения, но и его контекст, используемый рекламный канал. Полноцветная реклама на обложке стоит обычно в два-три раза дороже, чем черно-белая реклама той же площади на внутренних страницах. Бегущая строка на телеэкране в десятки раз дешевле видеоролика и примерно в той же степени менее эффективна. Переключение конкурента с дешевой рекламы на дорогую (или наоборот) представляет собой важный симптом, и конкурентной разведке надо понять, что за этим стоит. Это может быть новая маркетинговая политика либо увеличение (или урезание) рекламного бюджета. Даже такой простой вывод может оказаться практически полезным: не увести ли у конкурента лучших рекламистов и маркетологов?
Имеет значение и оценка размера объявления: чем оно меньше, тем хуже себя чувствует фирма-конкурент. В особенности важно отмечать факт удешевления рекламы, когда ранее шли объявления большого размера.
Количество и регулярность объявлений, публикуемых в конкретном рекламном издании, могут вывести на оценку критериев — как выбирался наиболее выгодный режим размещения рекламы и нет ли здесь ошибки. Например, компания-конкурент торгует водкой эконом-класса, а помещает рекламу в дорогих «гламурных» журналах. Хотя чаще бывает наоборот — товары, рассчитанные на очень богатых людей, рекламируются в дешевых изданиях. Оба просчета следует немедленно использовать в собственных целях. Можно предложить руководству своей фирмы договориться в рекламном издании о скидках для конкурента. Пусть и дальше тратит свой рекламный бюджет впустую.
С рекламных объявлений полезно начинать первое знакомство с фирмой-конкурентом. По номерам телефонов или указанному в объявлении адресу устанавливается местоположение офиса, по телефонам ближайших риэлтерских агентств — арендная плата или стоимость принадлежащего конкуренту офиса. Все это — первичные сведения о его финансовом положении[7].
Если рекламное объявление посвящено не только имиджу компании, но и конкретным товарам и услугам, работа становится еще более плодотворной. Важны не только наименования товаров и их ассортимент, большое значение имеет и форма подачи.
Если в первую очередь рекламируется конкретный товар, чуть ли не с указанием артикула, значит, именно этот товар доставляет наибольшее беспокойство конкуренту в части его сбыта. Тут уж должны начинаться какие-то активные действия. Можно вспомнить случай, когда мы указали нашему клиенту на специфику рекламных объявлений конкурента: они всегда начинались с названия предельно конкретного товара. Наш партнер подослал своего человека в данную конкурирующую компанию, и тот начал вести переговоры о закупках большой партии рекламируемого (и явно неликвидного) товара. Переговоры о закупках тянулись до той поры, пока в рекламных изданиях не исчезли объявления, где упоминался данный товар. После чего переговоры по причинам, кажущимся вполне объективными, неожиданно прервались.
Через некоторое время выяснилось: агент заказчика вел себя на переговорах столь правдоподобно, что конкурент увеличил свои запасы данного неликвидного товара чуть ли не вчетверо.
Так же анализируются результаты побед конкурента на всякого рода конкурсах, выставках, тендерах и других бизнес-состязаниях.
Все внимание — прилагательным
В большинстве языков мира существуют особые части речи, отражающие свойства. В русском языке — это прилагательные. Мы уже знаем о вольностях использования прилагательных, когда качества из одной сферы перетекают в другие, и что такое явление называется синестезией. Теперь нужно сделать еще один шаг, к использованию достижений науки, на этот раз — древней.
Античная философия задавала определенные правила рассуждений. Одно из них состояло в том, что каждый термин должен сопоставляться с противоположным понятием, антонимом. Невозможно понять «белое», если нет «черного». Древний грек не понял бы, что означает слово «стимул», если бы ему не объяснили, что такое «стипул». Современный человек привык обходиться обломками терминологических пар. Однако тем, кто занимается контент-анализом, поневоле приходится вспоминать античные правила, в рамках которых двойственность была обязательной.
Метод семантического дифференциала, созданный американским психологом Дж. Осгудом в середине прошлого века[8], базируется на парах прилагательных -антонимов. Скажем, вы просите оценить некоторого конкурента по непрерывной шкале. Опрашиваемый перечеркивает полоску там, где он считает нужным. Например, так:
неопасный _______________________опасный
Некогда в США проводились исследования по двум тысячам оппозиционных (антонимических) пар. Оценивались даже предметы обихода, мебель и другие очень знакомые предметы. Вопросы звучали зачастую нелепо. Например, к какому краю шкалы ближе ваше любимое кресло — оно в большей степени нервное или спокойное? Но удивительно, что после обработки результатов опроса оказалось, что все оцениваемые объекты в пространстве двух тысяч параметров распределялись вполне осмысленно.
В настоящее время многие применяют этот метод семантического дифференциала без исходного набора факторов (оценка, сила, активность), которые приведены выше в отношении характеристик цветов (см. табл. 1).
Так, в одном из крупных городов юга России метод семантического дифференциала использовался в исследовании имиджа крупного торгового центра. Экспертов и покупателей просили оценить конкретный супермаркет по четырем шкалам:
консервативный — новаторский
уверенный — неуверенный
успешный — безуспешный
сильный — слабый.
Такой подход заимствует только форму опроса, но игнорирует главное достижение метода семантического дифференциала — выделение трех базовых факторов: оценка, сила, активность, что делает метод практически бесполезным для контент-анализа. Остается лишь довольно простая идея непрерывной шкалы.
Метод семантического дифференциала придуман для экспериментов. Только впоследствии его стали использовать в контент-анализе, который решает обратную задачу — выявление скрытого (латентного) смысла сообщений, появившихся независимо от исследователя. И здесь налицо полная аналогия с классами задач, хорошо известными физикам. Есть прямые задачи, для решения которых проводится эксперимент, и есть обратные задачи, когда зафиксированы некоторые события или процессы и требуется выяснить, по каким правилам они происходили или протекали.
Таким образом, измерение семантического дифференциала в эксперименте есть часть решения прямой задачи, а контент-анализ текста с использованием метода семантического дифференциала представляет собой решение обратной задачи. Наилучшие результаты решение обратных задач дает при анализе текущих сообщений, исходящих непосредственно от конкурента.
Контент-анализ выступления, интервью или беседы
В контент-анализе используются три основные схемы классификации терминов, с помощью которых текст разбивается на значимые высказывания и тезисы. В первых двух текст обрабатывается наложением на него заранее разработанной системы терминов. Описанный выше метод семантического дифференциала — один из таких наборов терминов, который используется более полувека. Существует еще несколько таких же устойчиво сохраняющихся систем.
Система Бейлса была разработана для анализа речевых взаимодействий в малых группах[9]. В конкурентной разведке она полезна при анализе интервью (и бесед), которые дают руководители компании-конкурента.
Эту систему привожу в форме, которую придумал сам, хотя не исключено, что кто-нибудь сделал это и до меня. Все-таки от изобретения этой довольно популярной системы прошло более полувека. Но предлагаемая вниманию читателя структура изложения наиболее полезна для решения задач конкурентной разведки.
Система категорий Бэйлса состоит из трех уровней. Прежде всего, в словах собеседника или в содержании интервью ищут реакции двух типов: положительные и отрицательные (табл. 2). Затем и те и другие делятся на три подкатегории: решения, отражение напряженности и реинтеграция (стремление к большему взаимопониманию).
Таблица 2
Первая часть категориальной системы Бэйлса (реакции)
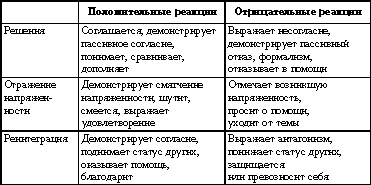
Чтобы читатель понял, почему я восторгаюсь системой категорий Бэйлса, приведу пример из категории «положительная реинтеграция»: «Я обращаюсь к Вам, как к специалисту...». В развернутой системе категорий Бэйлса, которая несколько отличается от описываемой, это называется «снижением напряженности разговора путем поднятия престижа собеседника».
Вторая часть системы категорий Бэйлса касается отношений, отраженных в высказываниях (табл. 3). Два критерия деления категорий второй части — вопросы и попытки ответить.
Таблица 3
Вторая часть категориальной системы Бэйлса (отношения)

Нетрудно заметить, что две группы категорий Бэйлса построены однотипно. Если нет желания применять в конкретных исследованиях собственно категории Бэйлса, то можно заимствовать саму идею, заложенную в данную систему. В концепции семантического дифференциала пары терминов предполагаются изначально независимыми, как бы равноположенными. В системе Бэйлса такими равными по значимости друг другу считаются две шестерки терминов. В первой шестерке (табл. 2) пассивная пара (положительная — отрицательная реакция) сочетается с активной (конструктивной) тройкой. Во второй шестерке терминов (табл. 3) активная пара (вопросы — попытки ответить) сочетается с пассивной тройкой.
Система Бэйлса хорошо зарекомендовала себя при анализе конструктивности позиции конкретного человека, а также при анализе изменений его позиции. Например, при использовании системы Бэйлса служба конкурентной разведки может дать заключение о целесообразности продолжения переговоров, уже начавшихся с конкурентом. Если в выступлениях последнего увеличивается доля неконструктивных высказываний, а также доля негатива и высказываний, в которых фиксируется собственное отношение, но нет конкретных предложений, то самое время предложить руководству прекратить переговоры.
Сборка терминов в категории — лингвистический подход
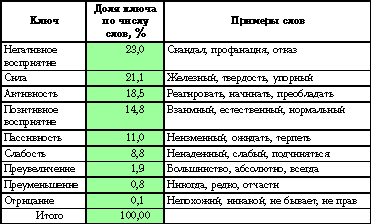
Второй вариант схемы классификации терминов, встречающихся в тексте, также опирается на классификаторы, истоки которых лежат не в психологии, а в лингвистике. Для анализа текстов на русском языке пока не разработано достаточно последовательной, ориентированной на контент-анализ лингвистической классификации терминов. Возможно, первым прорывом станет семантический словарь русского языка РУСЛАН, который пока находится в стадии разработки[10]. Но представление о том, какой подобная классификация должна быть, мы можем получить по тезаурусным ключам, разработанным для англоязычных текстов (табл. 4).
Таблица 4
Структура ключей Стэнфордского политического словаря в переводе на русский язык
Теперь сгруппируем в пары приведенные термины — получится всего лишь четыре с половиной пары (табл. 5).
Таблица 5
Структура пар ключей Стэнфордского политического словаря

Таким образом, ведущая пара — более трети всех терминов, относятся к восприятию автором некоторой стороны или элемента действительности, они говорят об авторе, а не о предмете сообщения. Уже это должно ориентировать исследователя на то, какую же информацию следует читать между строк, что наиболее вероятно.
Я привожу пример категорий наиболее известного политического словаря, разработанного в Великобритании. В США в последние годы активно используются специализированные словари для контент-анализа «Harvard IV-4» и «Lasswell».
Недостающий элемент пары
Лингвистические методы формирования оппозиционных терминологических пар неоднозначны. Когда термину недостает пары, приходится такую пару сочинять. Скажем, как подобрать пару к термину «агрессивность»? Одна пара: агрессивность — оборонительность, другая: агрессивность — пассивность, но можно составить и еще одну пару: агрессивность — аффиляция.
«Под аффиляцией (контактом, общением) мы подразумеваем определенный класс социальных взаимодействий, имеющих повседневный и в то же время фундаментальный характер. Содержание их заключается в общении с другими людьми (в том числе с незнакомыми и малознакомыми) и такое его поддержание, которое приносит удовлетворение, увлекает и обогащает обе стороны»[11]. Аффиляция выражает желание сотрудничать, уважение к аудитории, проявление симпатии. В общем аффиляция представляет собой искусственно сконструированный антоним агрессивности и выступлению с позиции силы. Как термин она наиболее точно противостоит категории «агрессивность». Эта категория начинает очень хорошо работать в самых неожиданных исследовательских ситуациях.
В исследовании В. И. Шалака исходным материалом были полторы тысячи поэтических произведений, авторы которых — 300 самых известных российских поэтов ХХ века (с 1900 по 2000 гг.)[12]. Слова, которые относились к категории «аффиляция», подсчитывались за последовательные пятилетние периоды. Фактическая частота таких слов сравнивалась с ожидаемой. И на рис. 2 показана динамика этого отклонения в течение всего ХХ века.
Рис. 2. Динамика категории «аффиляция» в течение ХХ века по данным поэзии
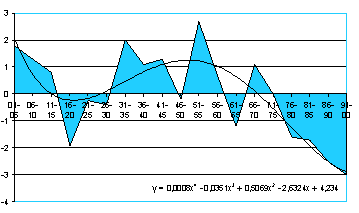
Мы видим, что доля слов российских поэтов, в которых отражается аффиляция, упала с началом Первой мировой войны и восстановилась только в 30-е годы. Несмотря на трудности и горести Великой Отечественной войны и послевоенного пятилетия, аффиляция была представлена на среднем уровне. Но начиная с первой половины 70-х годов аффиляция стала уходить из российской поэзии настолько быстро, что уже в начале 80-х была очевидна схожесть будущей истории нашей Родины с событиями, которые она переживала в начале века. Особо отметим, что в те времена экономисты говорили об ускорении, а политики — о социализме с человеческим лицом. Но поэты более точно предчувствовали всё, что произойдет в ближайшем будущем. Этот пример, по моему мнению, очень хорошо показывает ту пользу, которую способен принести контент -анализ, если применять его последовательно.
После этого можно поверить и в то, что даже самые простые количественные показатели, рассчитанные по тексту, например, средняя длина слова, дают информацию, которую невозможно выявить, вчитываясь в содержание текста. Для каждого автора средняя длина слова — величина постоянная. Поэтому, если руководитель компании-конкурента (или любого иного контрагента, за действиями которого целесообразно следить) неожиданно «выдает» текст, в котором средняя длина слова отличается от обычной для него, — это симптом. Симптом чего? А на этот вопрос должны ответить последующие разработки службы конкурентной разведки.
Порождение схемы категорий в процессе контент-анализа
Для понимания стратегических намерений конкурента полезно анализировать декларативные, внешне неинформативные его сообщения. Это могут быть пресс-релизы, выступления руководителей, но наибольший интерес представляют собой описания миссии компаний[13].
В качестве примера удачного применения контент -анализа в практическом экономическом прогнозе можно привести пример, касающийся банкротства американской компании Enron, которая длительное время скрывала свое предбанкротное состояние[14]. Этот прогноз был сделан post factum и потому, скорее, представляет собой демонстрацию возможностей контент-анализа, с помощью которого можно было бы предсказать будущее банкротство.
В упомянутом исследовании рассчитывалось соотношение (разница) долей конкретной и неконкретной информации. Чем ближе к банкротству, тем выше доля неконкретной информации, как ее ни считай — по количеству знаков или по числу предложений. Отсутствие конкретной информации в сообщении конкурента, при том, что до сих пор он обычно сообщал о каких-то реальных делах, может свидетельствовать о многом, и это можно выявить с помощью дополнительного изучения. Но общий вывод — в компании что-то идет не так.
По компании Enron соотношение конкретной и неконкретной информации падало с февраля 1996 г. по апрель 2001 г., и это говорило, что дела идут все хуже и хуже. При этом из самого содержания не следует, что дела плохи, скорее, наоборот. Но если доля неконкретной информации стабильно увеличивается, это значит, что компании есть что скрывать. А уж постоянное увеличение доли неконкретной информации должно вызывать подозрения в том, что что-то неладно. Последовательное монотонное изменение не может быть случайным[15].
При контент-анализе миссии одной крупной сибирской компании использовались, например, такие принципы контент-анализа без предварительно выделенных категорий терминов.
Все тексты состоят из событий (events), и только контекст увязывает их воедино. Восприятие текста обычным читателем предполагает неразрывность содержания и контекста, аналитик должен разделить их.
Чтобы выявлять скрытую, латентную информацию, содержащуюся в декларациях типа миссии компании, нужно научиться отделять события от контекста.
Контекст во многом додумывается читателем текста, текст пишется в расчете на такое додумывание, следует выйти из этого взаимодействия.
События всегда связаны между собой не только через контекст, но и как-то иначе.
События распадаются на объекты и действия, при этом в одних случаях объекты важнее действий, в других — наоборот.
Количественный объем событий говорит о том, что явно не включено в содержание текста.
В исследовании применялись два критерия для классификации событий, содержащихся в тексте. Первый критерий — формально-лингвистический, состоит в следующем. Если некоторое действие (намерение, пожелание) упоминается в тексте как глагол, являющийся сказуемым предложения, то это действие мы относим к основным. Если действие в тексте упоминается в форме деепричастного или причастного оборота, то это действие относится к второстепенным.
Второй критерий — содержательный, состоит в том, что если есть прямое указание на цель, то есть высказывание содержит элемент целеполагания, указания на цель, то это более важная часть миссии, чем если в событии упоминается намерение без указания цели. В результате применения этих двух критериев текст миссии распределился на следующие четыре группы, отображающие две дихотомии[16].
В результате миссия компании уложилась в четыре клетки таблицы (табл. 6).
Таблица 6
Препарированная миссия компании

Наиболее важные цели компании концентрируются в клетке «целеполагание — основное действие», наименее важные — в клетке «намерения — вспомогательное действие». Непосредственно из текста миссии компании такого упорядочения целей не следует. Но, будучи выявленной, иерархия целей позволяет выработать стратегическую линию борьбы с конкурентом, который занятие устойчивых позиций ставит выше освоения передовых технологий.
Семантические процессоры и хитроумное извлечение фактов
В настоящее время методы контент-анализа применяются к обширным текстам, с активным использованием специализированных программных средств.
Контент-анализу, ориентированному на понимание скрытой (латентной) позиции автора текста, в настоящее время противостоят схемы выявления фактов.
Что же такое факт в этой схеме? Для примера: если распознать в тексте, что произошла покупка акций, то автоматически должен быть построен стандартный набор сообщений — ответов на вопросы, кто покупатель, кто продавец, кто эмитент, сколько продано, каковы последствия. Существующие программные пакеты требуют указания, кто из трех действующих лиц является конкурентом. Досье могут быть построены только по одному из трех перечисленных выше действующих лиц.
Теперь можно определить, что же при таком подходе является фактом. Это не самое простое понятие в контент -анализе. Для того чтобы нечто было признано фактом, должен быть определен объект анализа. Если объект — фирма-конкурент, то ее одновременно следует признать и субъектом, то есть активным действующим лицом. Объект должен быть задан некоторым синонимическим рядом. И «Роман Абрамович», и «владелец Челси» и даже «главный чукотский футболист» должны автоматически преобразовываться в «руководство компании Сибнефть». Объектами мониторинга могут быть как персоны, так и организации. Должна быть построена система соответствий между теми и другими, причем систему эту, равно как и набор синонимов, следует постоянно актуализировать.
Чтобы избежать потока ненужной информации, определяются атрибуты объекта мониторинга, то есть те виды деятельности, которые в наибольшей мере интересуют конкурентную разведку.
В первых проектах сорокалетней давности (вспомните упоминавшийся анализ газет по упоминанию USA) выделялся только объект, а то, что говорилось о нем, анализировалось методом выдергивания нужных сообщений из беспорядочной их кучи. Сейчас другие времена, естественный интеллект в упадке, но зато крепчает интеллект искусственный. Одно из направлений исследований по искусственному интеллекту — так называемые семантические процессоры. Я в большей степени знаком с разработками в этой области, которые велись сначала в Вычислительном центре Сибирского отделения АН СССР, а теперь продолжаются в Российском НИИ искусственного интеллекта[17].
Другое направление разработки отечественных семантических процессоров представлено разработками компании «Гарант-Парк-Интернет», работающей в области компьютерной лингвистики[18]. На базе этих разработок, в частности, создана интеллектуальная программа RCO Fact Extractor, которая находит в тексте описания фактов заданного типа. Несколько программ семантического анализа, такие как Native Minds, noHold, FlexAnswer, Banter Inc., разработаны вне лингвистических процессоров[19].
Но прежде чем описывать работу семантического процессора того или иного типа, следует точно определить то, что в данной постановке считается фактом. По полушутливому определению Эйнштейна, прямая линия есть ось вращения абсолютно твердого тела. Точно так же и в семантическом контент-анализе факт есть выявленное в тексте событие, в котором замешан наблюдаемый объект по заранее зафиксированному атрибуту, то есть виду деятельности. Конкретизацией атрибута является тип факта, то есть конкретное действие, к которому имеет отношение объект наблюдения. Иногда тип факта называют значением атрибута. Пример типа факта из тех, что упоминались выше, — приобретение акций. Такова частная конкретизация атрибута «купля-продажа собственности». Один и тот же факт, относящийся к одному и тому же объекту мониторинга, может иметь отношение не к одному, а к нескольким его атрибутам.
Основная часть семантических процессоров строится как обучаемые системы. Если им показано (обычно на десятке примеров), какие наблюдать объекты, какие атрибуты этих объектов интересны для мониторинга, то специальная программа-настройщик построит шаблоны фактов каждого из исследуемых типов. В этом шаблоне, иногда называемом лингвистическим описанием факта (ЛОФ), или семантической сетью, указана полная его структура. Скажем, если вернуться к ситуации купли-продажи акций, то там должны быть три фигуранта: покупатель, продавец и эмитент плюс характеристики проданного или купленного пакета. По этому шаблону восстанавливается позиция объекта мониторинга в шаблоне (семантической сети): кто продавец или покупатель.
Собственно мониторинг состоит в том, что найденные факты, сгруппированные по атрибутам объектов, собираются в досье. Досье постоянно обновляется и служит хорошим сырьем для быстрого написания справки или отчета. Если упростить описание работы семантических процессоров, то можно сказать, что они выполняют единственную функцию. У них заготовлены вопросы анкеты, задача их — проверить, является ли данная часть текста (речи, выступления) ответом на какой-нибудь вопрос этой анкеты. К этой основной функции добавляются вспомогательные — как составить саму анкету и какими способами проверять. Прогресс в этой сфере настолько быстрый, что обе вспомогательные функции совершенствуются практически ежедневно. Но существо дела не меняется.
Появляются и новые вспомогательные функции. В частности, явное продвижение отмечается в выявлении семантических связей между предложениями. Это позволяет совершенно по-новому трактовать любой текст, практически полностью игнорируя синтаксис в той части, когда он не касается семантики.
Процедуры современного контент-анализа
Рассмотрим этапы контент-анализа при использовании того программного обеспечения (семантических и лингвистических процессоров), которое в настоящее время присутствует на рынке. Перечисленные процедуры показывают место человека в современном, ориентированном на использование компьютеров, контент-анализе.
Кодирование (или разметка текста) представляет собой основной по затратам этап контент-анализа. Существуют разные системы разметки текстов, основная часть их предполагает полуавтоматическую разметку. То есть нет ни одной системы, которая бы распознавала структуру текста без участия человека. Но существуют хорошие программные пакеты поддержки разметки, которые на порядок повышают производительность труда разметчика.
Категоризация представляет собой следующий уровень контент-анализа. На этом этапе из размеченных единиц анализа формируются немногочисленные категории типа тех, какие упоминались выше.
Классификация подразумевает стыковку единиц анализа и категорий. Хотя в этой процедуре встреченные в тексте слова не всегда могут быть легко и однозначно отнесены к какой-либо из категорий, эта процедура считается автоматизированной в наибольшей степени. Человек даже не в самых современных программных пакетах «подбирает» за компьютером не более 10% слов, которые не могут быть разнесены по категориям автоматически.
Подсчет и сравнение — следующий уровень, на который поднимается исследователь в ходе человеко -машинного контент-анализа. Подсчитываются и сравниваются количества фактов в разных категориях, по разным классам документов и в динамике. Некоторые сравнения делаются по каким-то временным вехам. Пример приведен выше, в связи с российской поэзией.
Получение выводов, как и в любом исследовании, представляет собой наиболее важный и сложный этап анализа. Основную роль в данной процедуре играет человек. Компьютер сделал свое дело на предыдущих этапах, в предшествовавших процедурах. Выводы отличаются от проведенных ранее сравнений и подсчетов тем, что они содержат скрытые (латентные) или явные рекомендации — что делать.
* * *
Теперь мы можем вернуться к упомянутой выше программе General Inquirer, которой насчитывается уже пятый десяток лет. Эта программа использует в настоящее время 182 семантических категории и пользуется словарем в сотни тысяч слов, которые поставлены в соответствие этим категориям. Только категория «отрицание» имеет соответствия с 2291 термином. При этом исследуются все смысловые оттенки каждого термина. Этот набор категорий складывался постепенно и продолжает совершенствоваться. Службам конкурентной разведки нужно начинать с какого-либо стандартного набора категорий, а затем постепенно притирать их к существу решаемых задач.
[1] Десятая статья из серии статей о конкурентной разведке. Предыдущие статьи см.: ЭКО. № 10—12. 2004 г.; № 2, 3, 5—7, 9. 2005 г.
[2] Подробнее см.: Воронов Ю. П. Из истории анализа содержания личных документов // Методологические и методические проблемы контент-анализа. М.-Л., 1973. Вып. 2. С. 120—121; Владыкин В. А., Воронов Ю. П. Контент -анализ и рецензирование научной литературы // Там же. С. 71—76. Последняя статья предваряет наши работы с социологом В. А. Владыкиным по анализу объявлений о приеме на работу, проводившихся в г. Рубцовске Алтайского края.
[3] Подробнее с этими рассуждениями можно ознакомиться в книге: Воронов Ю. П. Методы сбора информации в социологическом исследовании. М.: Финансы и статистика, 1973.
[4] Ядов В. А. Социологическое исследование: методология, программа, методы. М.: Наука, 1987; Ядов В. А. Стратегия социологического исследования Описание, объяснение, понимание социальной реальности. М.: «Добросвет», 2001; Степанова Л. А. Изучение экономического сознания методом семантического дифференциала // Социологические исследования. 1992. № 8.
[5] Авторство таблицы принадлежит американским психологам Адамсу и Осгуду, цитируется по: Яньшин П. В. Эмоциональный цвет. Эмоциональный компонент в психологической структуре цвета. Самара: СамГПУ, 1996. Это — некоторый элемент метода семантического дифференциала, о котором речь идет далее.
[6] Петренко В. Ф. Психосемантика сознания. М.: Изд-во МГУ, 1988.
[7] Эти сведения более надежны, чем информация о том, на каком автомобиле ездит руководитель компании конкурента. Еще пять-шесть лет все было наоборот.
[8] На русском языке метод семантического
дифференциала обычно изучали по статье: Осгуд Ч., Суси Дж.,
Танненбаум П. Приложение методики семантического дифференциала к
исследованиям по эстетике и смежным проблемам // Семиотика и искусствометрия.
М.: Мир, 1972. Сейчас лучшее изложение есть в главе 8 книги: Толстова Ю. Н.
Измерение в социологии: Курс лекций. М.: ИНФРА-М, 1998.
[9] Bales R. F. Interaction Process Analysis: A Method for the Study of small groups. AddisonWesley, Reading. Mass. 1950.
[10] См.: Леонтьева Н. Н., Семенова С. Ю. Семантический словарь РУСЛАН как инструмент компьютерного понимания // Понимание в коммуникации. Материалы научно-практической конференции 5—6 марта 2003 г. М.: МГГИИ, 2003. С. 41—46.
[11] Хекхаузен Х. Мотивация и деятельность. Цитируется по: Шалак В. И. Современный контент-анализ. М. Омега-Л, 2004. С. 50.
[12] Шалак В. И. Современный контент-анализ. С. 51. В книге есть также динамика контента поэтических произведений по таким категориям, как «власть», «жизнь», «смерть», «достижение», «фрустрация» и другие. Анализ приводимого далее графика сделан независимо от автора исследования. Линейный тренд заменен на полиномиальный, да и выводы несколько иные.
[13] В описании контент-анализа миссии компании использованы материалы второй главы книги: Воронов Ю. П., Добров А. П. Латентность стратегических решений и новые инструментальные средства. Новосибирск: изд-во ИЭиОПП СО РАН, 2005. С. 46—63. Рецензия на книгу опубликована в «ЭКО». 2005. № 9.
[14] Шалак В. Компьютерный контент-анализ текстов как метод экономической разведки // www.it2b.ru (дата опубликования —19.02.2004).
[15] Шалак В. И. Современный контент-анализ. В исследовании используются еще восемь различных количественных соотношений.
[16] См. материалы конференций: Проблемы обработки больших массивов неструктурированных текстовых документов, Москва, июль 2002 г.; Информационная безопасность компьютерных систем, ноябрь 2000 г.
[17] Основатель и руководитель РосНИИ ИИ — Александр Семенович Нариньяни, один из ведущих ученых мира в этой области; лабораторию, которая занимается семантическими процессорами, возглавляет Ю. А. Загорулько, и эта лаборатория продолжает работать в новосибирском Академгородке.
[18] Желающие подробнее ознакомиться с этим направлением контент-анализа см.: http://www.rco.ru
[19] Сравнительные характеристики подобных программ можно найти на сайтах http://www.intext.de/TEXTANAE.HTM (Германия) и http://www.gsu.edu/~wwwcom/content.html (США).